
Wie genau wird ein Prompt bei einem Chat AI Bot auseinander genommen und die Antwort erzeugt? Also Tokenizen der Anfrage, einen Binärbaum aufbauen mit den Wahrscheinlichkeiten für die entsprechenden Äste auf Grundlage der Daten des LLM.
Ein Prompt bei einem Chat AI Bot wird in mehreren Schritten verarbeitet, die auf den Prinzipien der natürlichen Sprachverarbeitung (NLP) und maschinellen Lernens basieren. Zunächst wird die Anfrage tokenisiert und anschließend von einem großen Sprachmodell (LLM) analysiert, das auf Wahrscheinlichkeiten für mögliche Antwort-Token basiert. Ein expliziter Binärbaum wird dabei jedoch nicht gebaut, sondern die Wahrscheinlichkeitsverteilung für die nächsten Token fortlaufend berechnet und meist als „Logits“ vorliegen.
Tokenisierung des Prompts
Nach Eingang des Prompts zerlegt das Modell den Text in sogenannte Token, was Wortteile, ganze Wörter oder auch Satzzeichen umfassen kann. Die Tokenisierung ist abhängig vom verwendeten Modell und dessen Vokabular. Moderne LLMs nutzen meist das Byte Pair Encoding (BPE) oder ähnliche Verfahren, um den Text möglichst effizient in Token abzubilden.
Wahrscheinlichkeitsberechnung der nächsten Token
Das Modell verarbeitet die Token sequenziell und berechnet für jedes mögliche nächste Token die Wahrscheinlichkeit, basierend auf den trainierten Daten und Kontextinformationen. Das Ergebnis ist eine Verteilung aller möglichen nächsten Token (die sogenannten „Logits“).
Entscheidungsprozess und Baummetapher
Statt eines ausdrücklich konstruierten Binärbaums entsteht eher ein „Pfad“ durch den Tokenraum:
– Für jeden Schritt (Token) entscheidet das Modell anhand seiner Wahrscheinlichkeitsverteilung, welches Token als nächstes gewählt wird.
– Der Prozess kann als „Baumerzeugung“ interpretiert werden, da aus jedem Zustand (Token) verschiedene mögliche Fortsetzungen („Äste“) mit jeweils einer Wahrscheinlichkeit entstehen.
– In der Praxis bleiben viele Äste unberücksichtigt, da Algorithmen wie Greedy Search oder Sampling nur die wahrscheinlichsten Varianten verfolgen.
Aufbau der Antwort
Die Antwort entsteht durch wiederholte Auswahl des wahrscheinlichsten oder eines mittels Sampling gewählten nächsten Tokens, bis ein Stoppkriterium erreicht ist (z.B. ein End-Token oder eine max. Länge).
Im Hintergrund liegt mathematisch für jeden Schritt die Berechnung:
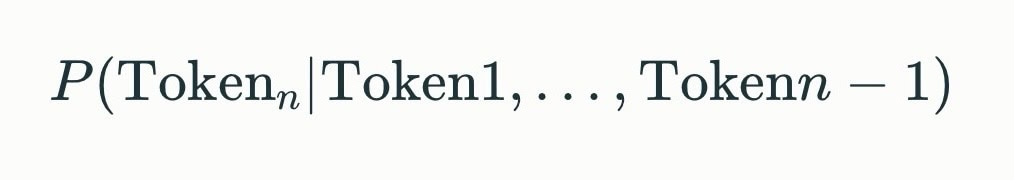
Diese Konditionalwahrscheinlichkeit wird für jedes Token berechnet und steuert die Antworterzeugung.
Fazit
Im Kern besteht der Ablauf aus:
– Tokenisierung,
– sequenzieller Wahrscheinlichkeitsberechnung,
– Auswahl des nächsten Tokens (als würde man einen Pfad im Baum entlanggehen),
– Wiederholung bis zur fertigen Antwort – aber der Baum wird nicht als vollständige Struktur aufgebaut, sondern Schritt für Schritt erzeugt.
Jeder dieser Schritte ist darauf optimiert, mit dem trainierten Modell schnelle und plausible Antworten zu generieren.
Quellen
– [Funktionsweise von ChatGPT und Tokenisierung](https://www.faz.net/aktuell/wissen/technik/die-kerntechnologie-von-chatgpt-wie-sprachmodelle-arbeiten-18594303.html)
– [Tokenisierung in modernen LLMs (BPE-Verfahren)](https://towardsdatascience.com/tokenization-in-nlp-29e410f8a502)
– [Textgenerierung und Entscheidungsprozesse in Sprachmodellen](https://ai.stackexchange.com/questions/36487/how-do-language-models-generate-text)
Zu beachten:
Ki ist mein Namenskurzzeichen und steht nicht für künstliche Intelligenz.
Wie immer gilt es zu beachten: KI-Systeme irren und fabulieren gerne. Einschalten des gesunden Menschenverstandes ist keine Option, sondern wird streng erwartet!
Hier wurde Perplexity genutzt.







 Niklaus Wirth (2005), Tyomitch •
Niklaus Wirth (2005), Tyomitch • 
{kind=link}